
期待値計算が容易な馬券種と困難な馬券種
KeibaAiNavi
競馬AIナビ


回帰分析は、統計学において、データ間の関係性を数学的に表現する方法です。
競馬のデータ分析においては、特定のファクター(独立変数)が回収率や勝率など(従属変数)にどのような影響を与えているかを予測するために使用します。
分析の結果は式やグラフで表すことができます。この式を用いてファクターの値毎の期待値を予測することができます。
具体例を見てみましょう。
.png)
こちらの青色のグラフは実際の過去データの値を示しています。しかし、当然ながら様々な偶然的要因によってきれいな直線や曲線にはならず、凸凹なグラフになっています。
回帰分析を行うことにより、その凸凹をなくし傾向をわかりやすくしたものが赤い直線です。
回帰分析を行うにあたり使用する基本的な用語から、分析結果等で目にする用語のうち、主なものまとめました。
最初からすべての用語を理解する必要はありませんが、分析を行う中でわからない単語が出てきた際に確認してみてください。
これらの用語をはじめとして、基礎知識や基本概念を理解することで、精度が高い回帰分析を行うことが可能となります。

実際に回帰分析を行う方法についてはさまざまありますが、その中でも特別な知識がなくとも簡単にできる方法を中心にご紹介します。
Excelで作成したグラフに、回帰分析グラフや数式を追加する方法を紹介します。
※Excelのバージョン等により、若干手順が異なる可能性があります。
TARGETで分析したいファクターを調べます。ここではダートレースの枠番別成績を調べてみます。
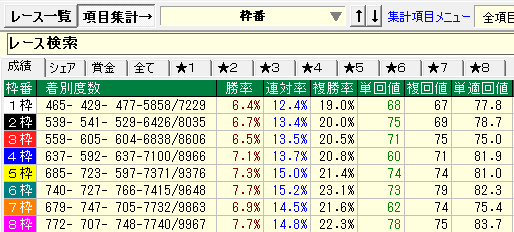
先ほどの結果をExcelに貼り付け、折れ線グラフ化します。
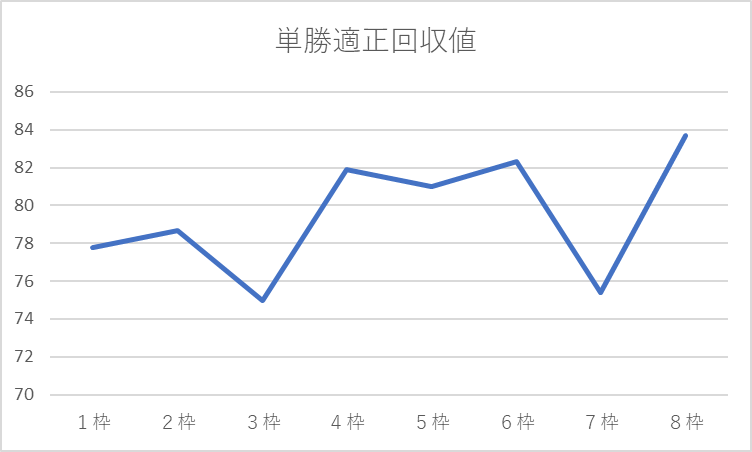
グラフ右上に表示される「+」マークにマウスを合わせ、表示される一覧の中から「近似曲線」にチェックを入れる
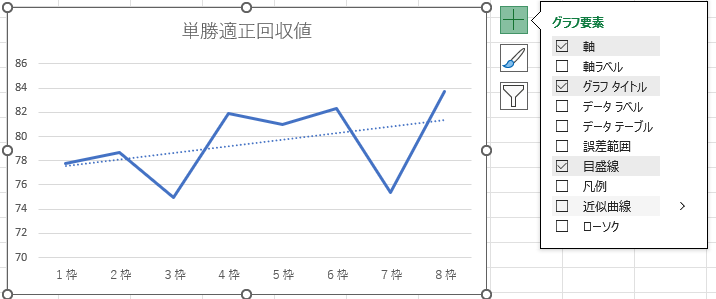
新たな点線がグラフに追加されます。これが直線(線形)の回帰分析結果結果となります。
新たに表示された点線部分をダブルクリックすると、Excel右側に「近似曲線の書式設定」が表示されます。
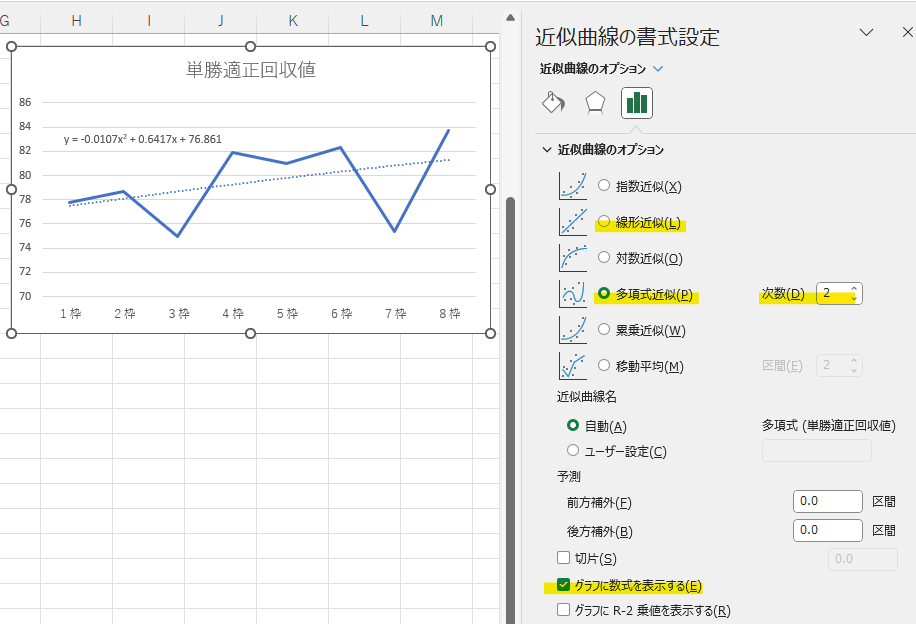
ここで「多項式近似」を選択することで、2次以上の関数型の近似曲線へ変更できます。直線が最も適している場合は「線形近似」を選択します。
どの次数が最も適しているか、次数を変更しながら確認してください。
また、下部にある「グラフに数式を表示する」にチェックを入れることで、回帰分析の結果を数式で表示することができます。
このように、Excelで非常に簡単に回帰分析を行うことができます。しかし、この方法には次のようなデメリットがあります。
各データ母数による重み付けや複数ファクターを掛け合わせた分析(多重回帰分析)を行うためには、より専門的な機能を使用する必要があります。その方法については別記事で解説します。
回帰分析の精度を上げるためには、事前の加工処理が必須となります。
特に、データの分母数が少ないものは、確率の偏りにより極端に高い(低い)回収率となっていることがあります。そのデータをそのまま使用してしまうと、ファクターごとの傾向を正確に捉えることができなくなってしまいます。
そのため、分析前にあらかじめ異常値を除去することが必要です。
こちらは、芝のレースにおける、人気順ごとの回収率をグラフ化したものです。
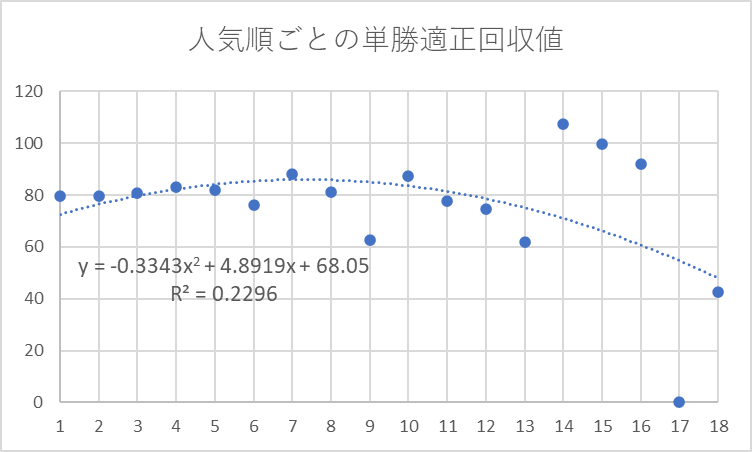
14番人気から16番人気は回収率100%前後と高くなっておりますが、一転して17番人気は回収率0%と極端に低くなっています。
これは、レースによって出走頭数が異なるため、下位の人気順になるほどデータの母数が少ないことが原因にあると想定できます。
ここで、14番人気以下を異常値として除外し分析してみます。
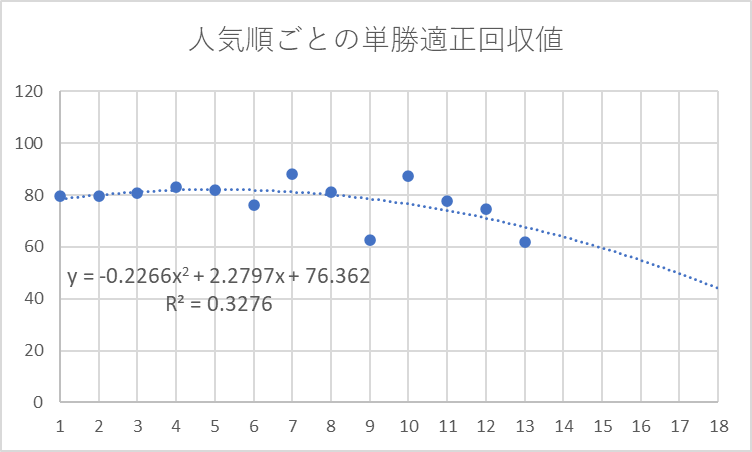
異常値を除去することで、上位人気馬の値についても、より適切に評価できるように見受けられます。
R2(決定係数)についても、0.2296から0.3276と上昇しており、よりファクターが回収率を適切に説明できているということを示しています。
このように、異常な値となっているデータを分析対象から除去することで、分析の精度を上げることが可能となります。
異常値を除去するにあたって、「どのような値であれば異常値とみなすか」を決める必要があります。統計学的にも異常値判断の方法は複数存在しますが、競馬の分析においては以下の2パターンのからの選択で問題ないと考えます。
こちらは単純に、一定の値以上・以下の回収率となっているデータを除去するという判断です。
その値の設定をどの程度にするかは個々人の判断により異なってきます。
しかし、十分な母数があるデータにおいては、1つのファクターで回収率100%を超えるということはほぼありません。そのため、私の場合は回収率60%以下、100%以上は基本的に異常値としてとらえています。
こちらはより統計学的アプローチによる判断となります。
データの分布が正規分布であるという仮定の下、加重平均からどの程度乖離しているかを基準として異常値を判定します。
絶対値を基にした判断と比べると、専門的であり、また計算処理が必要となるため、難易度が高い方法となります。
統計学に基づいて、様々なファクターを回帰分析することにより、期待値を数値化することが可能となります。
いきなり専門的な分析を行うのではなく、まずはExcelの「近似曲線」を作成する機能を使用することで、専門的な知識がなくとも簡単に分析を行うことを推奨します。
その際、あらかじめ異常値となるデータを除去することで、分析の精度が向上します。異常値の判定方法はいくつか存在しますが、まずは一定の値以上(以下)のデータを除外するという方法でも十分に分析精度の向上が見込めます。
こうした分析により、過去のデータを適切に評価し、各馬の指数算出に活用しましょう。




